Die Macht des Volkes
Ich bin ein politischer Mensch. Das ist denen, die mich kennen, sicher nichts Neues. Ich vertrete sogar die Meinung, dass alles politisch ist, wenn Menschen aufeinander treffen. Terminvereinbarungen in der Skatrunde sind auch politisch. Es ist vermutlich nicht ganz die wissenschaftliche Definition, aber ich fahre damit sehr gut: Politik ist all das, was das Miteinander-Auskommmen zwischen Menschen angeht.
Heute habe ich mich hingesetzt, um diese Gedanken festzuhalten, weil mehrere Dinge zusammengekommen sind. Die AfD hat die NGO-Files veröffentlicht und eine Bekannte hat auf Facebook einen Beitrag geteilt, wo jemand mal die Kommentare zu einem seiner vorigen Beiträge analysiert hat.
In beiden Gelegenheiten kommt der Punkt der Finanzierung und der Vernetzung als Vorwurf vor. Was ich komisch finde. Ich meine, nicht aus den offensichtlichen Gründen. "Follow the money", ist ein beliebter Ausspruch, um herauszufinden, wer wessen Interessen dort vertritt, ganz der alten Redewendung nach: "Wes Brot ich ess', des Lied ich sing'".
Das Spannende aber ist, dass –im Fall der NGO-Files ganz konkret, im anderen Falle eher beiläufig– die staatliche Förderung kritisiert wird. Ja, der Staat gibt Geld aus, um Nichtregierungsorganisationen ihre Arbeit zu ermöglichen. Wie dieses Geld ausgegeben wird, ist sicher kritikwürdig, aber das ist nicht mein Thema hier. Viel mehr kommt das Argument, dass eine staatliche Förderung einhergehe mit einer gewissen Pflicht zur Neutralität, und das finde ich schräg, aus zweierlei Gründen.
Der erste Grund ist recht schnell durch: Natürlich ist so eine Neutralität Murks (herrlich, dass ich hier diese Wortwahl nutzen darf). NGOs –die, um die es hier geht– haben sich der Zivilgesellschaft verpflichtet und demokratischen und rechtsstaatlichen Pflichten. Wie auch immer geartete Diskriminierung oder gar Unterminierung von Rechtsstaatsprinzipien oder der Demokratie sind dabei vollkommen fehl am Platze. Die gleiche Argumentation gilt auch für Staatsdiener*innen in der Schule, bei der Polizei oder in anderen Ämtern. Im besten Bürokratendeutsch wird das als Treue zur FDGO, der freiheitlich-demokratischen Grundordnung, bezeichnet.
Der andere Punkt ist ein wenig abstrakter. Der Staat, das sind wir. Wir alle. Unsere Steuern sind unsere Mittel, um gemeinschaftliche Aufgaben auf die Schultern der ganzen Gemeinschaft zu verteilen. Steuern und ihre gerechte Erhebung sind ein ganz eigenes Thema, aber im Grundsatz gilt: Wer viel verdient, trägt viel bei. Aber in der Demokratie sind alle gleichberechtigt. Aus einem größeren Beitrag sollte sich keine größere Mitbestimmung ergeben, auch wenn das in der Praxis und natürlich nur höchst inoffiziell ganz anders aussehen kann.
Wenn der Staat also NGOs Gelder gibt, um ihre Arbeit zu ermöglichen, dann sind wir alle das, die NGOs finanzieren. Unsere real existierende Demokratie hat an vielen Ecken und Enden ihre Defizite, aber die Arbeit solcher NGOs ist es nicht. Ganz im Gegenteil sehe ich in solchen zivilgesellschaftlichen NGOs die Möglichkeit unseres Gemeinwesens ein Korrektiv zu schaffen, dass Defizite in unserem Staat identifiziert, benennt und auf Verbesserungen hinarbeitet. Im gemeinschaftlichen Sinne und zum Wohl des Gemeinwesens. Dabei ist die FDGO nicht die Zielniveau, sondern bestenfalls die untere Grenze.
Ich finde den Einwand, dass der Staat so was nicht finanzieren müsse, durchaus fair. NGOs könnten ja auch ganz konkret um Spenden werben. Die Werbebanner meines Arbeitgebers sind jedes Jahr zur Weihnachtszeit ganz besonders "beliebt". Das passiert also auch, aber so manche NGO braucht wohl einen deutlich höheren Anteil an Staatsfinanzierung. Das Einwerben von Geldern von unterschiedlichster Seite ist ein Gebiet, wo spezialisierte Fundraiser*innen tätig sind.
Jetzt ist es aber so, dass in den vergangenen Jahren häufig auffällig wurde, wer von Seiten der AfD und ihrer Unterstützer*innen im In- und Ausland attackiert wurde. Und nicht nur von der AfD, sondern in anderen Ländern eben auch vergleichbare Einrichtungen von den dortigen zur AfD vergleichbaren Akteuren.
Die Wikipedia hat sich als Hauptziel vieler Akteure erwiesen, weil die crowdgesourcten Inhalte sich einer einfachen Einflussnahme entziehen. Russland und Elon Musk haben deswegen ja auch eigene Projekte angestoßen, um der Wikipedia ein Gegennarrativ in ihrem eigenen Sinne entgegenstellen zu können. Andernorts wird der Zugang zur Wikipedia gleich ganz gesperrt, um zu verhindern, dass die für die Wikipedia ausgehandelten neutralen und enzyklopädischen Einträge gelesen werden können. Bislang hat keine Demokratie die Wikipedia gesperrt – das waren immer Autokratien. Ich denke, der Punkt wird noch wichtig.
Der öffentliche-rechtliche Rundfunk, der ÖRR, ist auch ein beliebtes Ziel für Angriffe rechter und autoritärer Kräfte, sowohl hierzulande wie auch in der Schweiz wie auch Österreich. Kritik an der BBC gibt es in den UK reichlich. Das Trump-Regime in den USA hat noch im ersten Jahr die Finanzierung der Voice of America, des NPR und des PBS stark zurückgefahren.
Gemein ist all diesen öffentlichen Nachrichtenanbietern, dass sie dank der staatlichen (USA) oder gemeinschaftlichen (D, A, CH, UK) Finanzierung eine gewisse marktwirtschaftliche Unabhängigkeit besitzen, die ihnen redaktionell auch Freiheiten verschafft.
Redaktionelle Freiheit und Unabhängigkeit sind die eigentlichen Angriffsziele. Von einer Marginalisierung der jeweiligen Angebote profitieren immer die privaten Anbieter, die praktisch immer unter der Kontrolle einiger weniger Oligarchen stehen. In den USA hat sich mit der Warner-Bros-Übernahme durch Paramount ein Medienriese unter Kontrolle der Ellisons gebildet. Der Vater Larry Ellison ist Chef von Oracle und Trumpunterstützer. Vor einem Jahrzehnt hat Jeff Bezos –Chef und Gründer von Amazon und einigen anderen Unternehmen, kurzzeitig reichster Mann der Welt usw.– sich die Washington Post gegönnt, deren redaktionelle Unabhängigkeit zunehmend anzuzweifeln ist. In den UK haben die Murdoch-Medien seit Jahrzehnten die Polarisierung im Sinne von Murdoch Senior vorangetrieben, und sie sind sicher auch maßgeblich Schuld am Brexit, zumindest aber an der allgemeinen Sicht der Briten auf die EU. Hierzulande haben wir den Axel-Springer-Verlag, wo Friede Springe Matthias Döpfner weitestgehend freie Hand lässt. Erst die Tage wurde ein mutmaßliches Vier-Augen-Gespräch zwischen Döpfner und Merz wieder Thema, weil ersterer letzteren zur Duldung durch die oder Zusammenarbeit mit der AfD bewegen möchte, so heißt es. Dabei solle es wohl zu etwas härteren Worten gekommen sein. Der Chef der CompuGroup Medical, Frank Gotthard, hat in den letzten Jahren zweifelhafte Berühmtheit durch die Finanzierung des TV-Senders Nius erfahren, für den Julian Reichelt entscheidend tätig ist. Julian Reichelt, ehemals Chefredakteur bei der Bild, Axel-Springer-Verlag, und Vertrauter von Matthias Döpfner.
Unter den Überreichen ist es eine Art Hobby, sich Medien zusammenzustellen, die die öffentliche Meinung in ihrem Sinne beeinflussen soll. Deren maßgebliche Konkurrenz sind Medien, die eben nicht einzelnen Oligarchen hörig sind, sondern im Gegenteil sogar eine Unabhängigkeit von diesen besitzen, z.B. durch gemeinschaftliche oder steuerliche Finanzierung.
Wir als Gemeinschaft, wir als Staat, sind die Gegenthese zu den Überreichen und Oligarchen. Nominell gehören diese auch zu unseren Gesellschaften, aber de facto nutzen sie ihre Vermögen, um sich dieser Zugehörigkeit zu entledigen. Solidarische oder gemeinschaftliche Aufwände sollen auf das Minimum zurückgefahren werden, dass sie brauchen, um ihre Vermögen zu bewahren und zu vermehren.
Jetzt gibt es aber gelegentlich auch Überreiche, die einen sehr kritischen Blick auf diese Verhältnisse haben. Sie sind sozusagen Nestbeschmutzer unter ihresgleichen. Ich schlage jetzt den Bogen zu den Kommentaren unter dem Facebook-Beitrag. Dort wird George Soros bzw. Finanzierung durch George Soros kritisiert. Natürlich immer im Rahmen einer vermeintlichen jüdischen Weltverschwörung, denn Soros ist "unglücklicherweise" Jude. Ich hätte es mir gewünscht, wenn ein Nicht-Jude, am besten ein Christ, täte, was Soros getan hat, allein um all dieser antisemitischen Hetze gar nicht erst Brennstoff zu liefern.
Ich nehme Soros ab, dass er für offene Gesellschaften eintritt, für Demokratie und Bürgerrechte. Und als Mensch, der unverhofft zu großem Wohlstand gekommen ist, nutzt er das eben, um NGO-Arbeit zu ermöglichen. Für Antisemiten ist das natürlich ein gefundenes Fressen. Und für die oligarchisch kontrollierten Medien ist sein Engagement natürlich kontraproduktiv. Sie mögen nicht so weit gehen, und ihn direkt angreifen, aber sie haben keine Probleme damit, die Akteure zu unterstützen, die diese Angriffe fördern und gutheißen.
Aber das ist alles eigentlich "nur" ein Exkurs, um auf diesen Punkt zu kommen: Die Interessen der Überreichen werden schon allein durch die Möglichkeiten der Überreichen hinreichend bedient. Der Staat, also wir als Gemeinschaft, braucht nicht die Stimmen derer verstärken, die bereits laut sind. Tatsächlich bin ich überzeugt, dass deren Stimmen bereits so laut und vernehmlich sind, dass der Staat, also wir als Gemeinschaft, ein Gegengewicht unterstützen müssen, um die leisen Stimmen, die schüchternen Stimmen hörbar zu machen.
Und Stimmen, das sind nicht nur die Medien, die ich in den letzten Absätzen erwähnt habe. Das sind auch NGOs, die Lobbyarbeit betreiben für die, die keine Millionen und Milliarden in der Hinterhand haben, für Behinderte, für Flüchtlinge, für LGBTQIA+, für Frauen (wenn auch keine Minderheit, so doch immer noch marginalisiert). All diese Gruppen und noch mehr wollen diejenigen zum Schweigen bringen, die danach rufen, dass der Staat die Finanzierung dafür einstellen möge.
Die Macht des Staates kommt vom Volke. Diese Macht ist die einzige, die Oligarchen und Überreiche fürchten müssen. Und deswegen arbeiten sie daran, diese Macht zu zähmen.
IPv6 und LXC
Erster Urlaubstag. Die letzten drei Tage auf Arbeit hatte ich mir auf ein Thema vorgenommen, das mich schon seit geraumer Zeit stört: Unsere selbst betriebenen Dienste waren nicht per IPv6 erreichbar. Dazu muss man wissen, dass wir eine eigene Herangehensweise haben. Heutzutage wird ja viel über Docker und OCI-Images gemacht, aber wir betreiben unsere Dienste in Linux Containern, LXC. Die Dienste selbst sind auch per IPv4 nicht direkt erreichbar, sondern werden per Port Forwarding auf einen LXC mit einem nginx Reverse Proxy erreichbar gemacht. Zumindest die Webdienste. Im Falle anderer Dienste werden die Ports ggf. auf die jeweiligen Container durchgeleitet.
Im Default-Setup liefert Docker schon eine Menge Automatismen mit, um Ports von Containern zu exponieren, aber ich habe nicht viel Erfahrung mit Docker, das muss ich offen zugeben. Mein Eindruck aus den Installationsanleitungen diverser per Docker verteilter Webdienste ist aber, dass alle davon ausgehen, dass sie auf dem Host der einzige Webdienst seien und sich die Ports 80 und 443 krallen könnten. Zumindest der Caddy- oder nginx-Docker-Container müsste also manuell konfiguriert werden.
Aber es soll hier nicht um Docker gehen, sondern konkret um LXC, wobei vieles auch auf Systemcontainer, die auf systemd-nspawn basieren, und virtuelle Maschinen, die mit libvirt, kvm und qemu erstellt wurden, anzuwenden ist. Vielleicht auch VirtualBox, wobei mir das auf dem Server suspekt ist 😃. Grundsätzlich ist das anwendbar auf alle Lösungen, die sich einfach nur ohne Weiteres an ein Bridge-Interface hängen lassen.
Das Szenario
Ich habe mir für meine Versuche eine Cloud-VM bei Hetzner erstellt, das kleinste Modell für 2,99€/Monat. Als Betriebssystem kommt ein Debian 13 (Trixie) zum Einsatz.
Da ich mich auf IPv6 konzentrieren wollte, habe ich auf eine IPv4-Adresse verzichtet. Wenn ich mich recht erinnere, hieß es im Setup, dass IPv6 kostenlos sei, IPv4 aber mit 0,8ct/Stunde berechnet würde. Leider erstreckt sich das kostenlose IPv6-Angebot nur auf /64-Prefixe (ich bleibe bei der englischen Schreibweise, da Websuchen eher darauf ansprechen). Für einen kürzeren Prefix müsse man bezahlen, 15 Euro Bearbeitungsgebühr.
Als Grundlage der Netzwerkkonfiguration wollte ich systemd-networkd verwenden. systemd-networkd bringt meines Wissens alle Komponenten mit, um IPv6 auf dem Host und Downstream zu konfigurieren. Wer systemd meiden möchte, wird hier nicht glücklich. Ich denke aber, dass sich vieles auch auf ifupdown und radvd übertragen lässt. Ich habe keine Ahnung, welche DHCP-, DHCPv4- und DHCPv6-Komponente aktuell angesagt ist, wenn man systemd-networkd meiden will – ISC DHCP, Kea, dnsmasq? Und ob eine DHCPv6-Komponente überhaupt benötigt wird.
Privat nutze ich gerne systemd-nspawn anstelle von LXC, womit aber mein Arbeitskollege bereits vertraut war, als er das Thema Containerisierung bei uns bekannt machte. Ich finde es spannend, die Gemeinsamkeiten und Unterschiede zwischen den beiden letztlich auf demselben Fundament (Namespaces und Control Groups) aufsetzenden Ansätzen auszuloten. Beide bringen eine Menge Automatismen mit, manchmal für dasselbe Problem bei beiden, manchmal aber auch nur bei dem einen oder dem anderen. Im großen und ganzen sehe ich systemd-nspawn aber bei den Automatismen vorn (für mich besonders wichtig: Portfreigaben!). Das soll nicht heißen, dass man sie nicht nachvollziehen kann. Aber hier kommt LXC zum Einsatz.
Das Setup
Netzwerk
Hetzner konfiguriert die VMs per Cloud-Init. Dazu wird aus der Cloud-Init eine Netzwerkkonfiguration /etc/network/interfaces.d/50-cloud-init erstellt und der Dienst networking.service gestartet. Diese Konfiguration wird erst einmal auf systemd-networkd umgestellt.
# /etc/systemd/network/eth0.network [Match] Name=eth0 [Network] DHCP=no LinkLocalAddressing=ipv6 Address=2001:db8:900d:1dea::1/64 Gateway=fe80::1 DNS=2a01:4ff:ff00::add:1 DNS=2a01:4ff:ff00::add:2 IPv6AcceptRA=true
Die frisch erstelle Konfiguration bringt noch gar nichts, weil systemd-networkd.service noch nicht läuft:
systemctl enable --now systemd-networkd.service systemd-resolved.service
Das funktioniert und macht auch nichts kaputt. networkctl status zeigt dann, dass die Schnittstelle eth0 erfolgreich konfiguriert wurde. Jetzt muss nur noch ifupdown ausgeschaltet werden:
systemctl disable --now networking.service
Und so fand ich heraus, dass der Dienst nicht einfach gestoppt und deaktiviert wird, sondern auch die konfigurierten Schnittstellen in den down-Zustand bringen will. Gut, dass ich ein root-Passwort gesetzt hatte.
In der ausgelieferten Config gibt es einen Hinweis, wie man Cloud-Init mitteilt, keine Netzwerkkonfiguration mehr zu erstellen, ansonsten wird das immer wieder gemacht, und ich nehme an, dass auch networking.service immer wieder gestartet wird.
# This file is generated from information provided by the datasource. Changes
# to it will not persist across an instance reboot. To disable cloud-init's
# network configuration capabilities, write a file
# /etc/cloud/cloud.cfg.d/99-disable-network-config.cfg with the following:
# network: {config: disabled}
LXC
Eines der Quality-of-Life-Features von LXC ist die Möglichkeit, ein fertiges Image aus einem Repository zu laden:
lxc-create -n ipv6-client -t download -- -d debian -r trixie -a amd64
Das download-Template wird im Paket lxc-templates bereitgestellt. Ich habe weder die /etc/defaults/lxc noch die /etc/lxc/default.conf angepasst. Am Ende werde ich das eine oder andere erwähnen, was vielleicht noch sinnvoll wäre, aber ich reproduziere das hier eh schon aus dem Gedächtnis, solange es noch halbwegs frisch ist, und kann nicht gewährleisten, dass alles 100 Prozent korrekt ist.
Eine der Voreinstellungen von LXC ist, dass neu erstellte Container eine virtuelle Schnittstelle vom Typ veth bekommen, die an der Bridge lxcbr0 hängt. Um die Erstellung kümmert sich ein Skript, das über den Dienst lxc-net.service gestartet wird und in /usr/libexec/lxc/lxc-net liegt. Schaue ich mir das an, wird viel von der Schnittstellenkonfiguration direkt über ip-Befehle erledigt. Ich habe keine Lust, das alles zu replizieren, also fasse ich diese Schnittstelle für meine Experimente besser nicht an. Außerdem ist es vielleicht ganz sinnvoll, wenn die LXC untereinander in einem privaten Subnetz reden können und nur selektiv exponiert werden.
Ich ändere also die Konfiguration /var/lib/lxc/ipv6-client/config vom LXC ipv6-client und ergänze ein paar Zeilen:
# /var/lib/lxc/ipv6-client/config # lxc.net.0 ist die vordefinierte Schnittstelle aus der Default-Config, # deswegen hier lxc.net.1 lxc.net.1.type = veth lxc.net.1.link = br0 lxc.net.1.flags = up
Damit das funktioniert, brauche ich eine Schnittstelle br0 auf dem Host.
Bridge
Es braucht ein Network-Device in systemd-networkd:
# /etc/systemd/network/br0.netdev [NetDev] # Der Name kann beliebig gewählt werden. Name=br0 Kind=bridge
Und für dieses Device auch eine passende Network-Definition:
# /etc/systemd/network/br0.network [Match] # Der Name aus dem NetDev oben muss hier gematcht werden. Name=br0 [Network] IPMasquerade=no LLDP=yes EmitLLDP=customer-bridge
Nach einem networkctl reload ist die Bridge br0 sofort da. Wird der LXC gestartet, lxc-start ipv6-client, dann wird die zweite Schnittstelle eth1 an br0 gehängt.
Wie kriegt eth1 jetzt aber eine IPv6?
Irrwege
Weiß man, wie es richtig geht, könnte der Beitrag in den nächsten Absätzen enden. IPv6 ist aber für mich und uns im Team immer noch ein neues Thema, Neuland sozusagen. Der Leidensdruck, von IPv4 wegzukommen, war bislang nicht sonderlich groß. IPv6 ist ja letzten Monat auch erst 30 Jahre alt geworden (wir haben Teammitglieder, die jünger sind 😀).
IPv6 erfordert Umdenken. Manche Konzepte sind gänzlich neu. Auch nach dieser Erfahrung ist mir das Zusammenspiel zwischen RA, DHCPv6 und SLAAC noch nicht abschließend klar.
Meine Vorstellung war: Auf dem Host ist ein Prefix auf der Uplink-Schnittstelle eth0 konfiguriert. Ich sage der Schnittstelle: »Hey, annonciere doch mal, dass wir dieses Prefix haben, und zwar auf folgenden Schnittstellen: …«
Okay, so geht das nicht, aber ich kann doch br0 sagen: »Hey, frag doch bei eth0 an, welchen Prefix wir haben!«
Zumindest mein erster Versuch dahingehend war nicht erfolgreich, vielleicht geht das auch nicht. Ich habe die Konfiguration von eth0 dann weitgehend auf br0 übertragen und eth0 dann als Mitglied bei br0 eingehängt. Das hat … Wirkung gezeigt. Nur leider nichts Robustes. Immerhin konnte die eth1 im LXC dann eine IPv6 beziehen, aber der Verkehr war merkwürdig gestört: Beim Ping kam das erste Paket durch, dann 12 Pakete verloren, 1 Antwort, 12 Pakete verloren, und irgendwie hat sich das dann nach einer halben bis zwei Minuten stabilisiert.
Das war unbefriedigend. Manche Sachen wollte sich auch überhaupt nicht pingen lassen.
Und das war alles, nachdem ich bereits anderthalb Tage darauf verwendet hatte, IPv6-Prefix-Delegation zu konfigurieren. Ich will nicht ausschließen, dass es mit einem /64-Prefix nicht doch irgendwie gehen könnte, aber es ist nicht vom Protokoll vorgesehen, Prefixe größer als /64 zu delegieren. Ich denke auch, dass gewisse Unterschiede im Begriff "Delegation" zwischen deutsch und englisch hier hineinspielen. Tatsächlich muss man das so verstehen, dass die komplette Verantwortung für einen Prefix von einer Schnittstelle auf eine andere abgetreten wird. Es ist nicht so zu verstehen, dass nur die Kenntnis von einem Prefix einer anderen Schnittstelle mitgeteilt wird.
Die Prefix-Delegation dient wirklich nur dazu einen Prefix kleiner als /64 in größere Prefixe aufzuteilen, also z.B. ein /48 in mehrere /56 oder ein /56 in mehrere /64. Inwiefern die Länge immer ein Vielfaches von 8 (oder 4?) sein muss, kann ich nicht sagen. Ich glaube im Web auch Beiträge gesehen zu haben, wie ein /60 in mehrere /64 aufgeteilt wurde.
Hetzner, wie oben erwähnt, gewährt einem kostenlos nur /64er-Prefixe. Für meine Tests wollte ich jetzt nicht einen kleineren Prefix buchen. Für viele, die es irgendwann hierher verschlägt, dürfte /64 der Normalfall sein. Ich hoffe, ich kann jemanden hiermit die Zeit ersparen, es mit Prefix-Delegation zu probieren. Und ich hoffe, dass ich eines Tages doch noch praktische Verwendung für Prefix-Delegation finden kann.
Die Lösung, …
… erster Teil
Auf dem Host werden eth0 und br0 erstmal als separate Schnittstellen konfiguriert. br0 erhält zwei neue Abschnitte, [IPv6Prefix] und [IPv6SendRA]:
# /etc/systemd/network/br0.network … [IPv6Prefix] Prefix=2001:db8:900d:1dea::/64 Assign=true # ::1 ist eth0 Token=static:::2/64 [IPv6SendRA] UplinkInterface=eth0
Und im Abschnitt [Network] werden auch noch ein paar Zeilen ergänzt:
# /etc/systemd/network/br0.network [Network] … IPv6AcceptRA=true IPv6SendRA=true IPv6Forwarding=true
Die Zeile IPv6SendRA=true bewirkt, dass Router Advertisements auf der Schnittstelle erzeugt werden, mutmaßlich mit den Angaben aus dem Abschnitt [IPv6Prefix]. Die Zeile IPv6AcceptRA=true bewirkt, dass die Schnittstelle die Router Advertisements auf der Schnittstelle akzeptiert
Die drei Doppelpunkte nach static sind wichtig. Der erste Doppelpunkt trennt static von der IPv6-Adresse, die anderen beiden Doppelpunkte sind Teil der IPv6-Adresse. Sieht komisch aus, ist aber so.
Mit den Änderungen haben auf dem Host eth0 und br0 Adressen mit dem Prefix und der LXC ipv6-client hat sich ebenfalls eine Adresse mit dem Prefix konfiguriert.
Ich kann den Host anpingen, sowohl mit der IPv6-Adresse von eth0 wie auch der von br0. Das ganze Prefix wird auf diesen Host geroutet, wie man es auch erwarten mag. Aber die IPv6-Adresse vom LXC ist nicht erreichbar.
… zweiter Teil
Zwischendurch war mir zwar schon aufgefallen, dass ich auf dem Host zwei Routen habe für das /64-Netz, aber ich habe mir nichts weiter dabei gedacht. Mein Kollege kam dann auf die Idee, die Adresse auf eth0 doch einfach mit /128 zu konfigurieren. Ich griff den Vorschlag sofort auf:
# /etc/systemd/network/eth0.network … [Network] Address=2001:db8:900d:1dea::1/128
Und tatsächlich funktioniert das so. Auf dem Host wird nun eine Route zur /128er-Adresse gesetzt, für die eth0 zuständig ist, ansonsten ist br0 für das /64 zuständig. Die Adressen sind alle anpingbar, der LXC ist exponiert, auch ssh auf den LXC funktioniert, wie ich es erwarte.
Ist das eine saubere Lösung? Ich habe keine Ahnung.
Zusammenfassung
Das Network-Device für br0 hat sich nicht geändert. Die Network-Konfiguration sieht ungefähr so aus:
# /etc/systemd/network/br0.network [Match] Name=br0 [Network] Description=bridged uplink interface LinkLocalAddressing=ipv6 # See section [IPv6Prefix] IPv6SendRA=true IPv6AcceptRA=true IPMasquerade=no LLDP=yes EmitLLDP=customer-bridge IPv6Forwarding=true # See section [Network] [IPv6Prefix] Prefix=2001:db8:900d:1dea::/64 Assign=true Token=static:::2 [IPv6SendRA] UplinkInterface=eth0
Für eth0 auf dem Host gibt es das hier:
# /etc/systemd/network/uplink.network [Match] Name=eth0 [Network] Description=physical uplink interface LinkLocalAddressing=ipv6 Address=2001:db8:900d:1dea::1/128 Gateway=fe80::1 DNS=2a01:4ff:ff00::add:2 DNS=2a01:4ff:ff00::add:1 LLDP=yes EmitLLDP=customer-bridge IPv6Forwarding=true
Unerwähnt blieb bislang die Netzwerkkonfiguration von eth1 im LXC, aber sie ist eigentlich nicht besonders:
# /etc/systemd/network/eth1.network [Match] Name=eth1 [Network] DHCP=ipv6 IPv6AcceptRA=true [DHCP] ClientIdentifier=mac [DHCPv6] UseDelegatedPrefix=true
Ich nehme an, da kann noch einiges rausgeworfen werden.
Mögliche Verbesserungen
Ganz oben auf der Liste steht bei mir, der eth1 des Containers eine MAC-Adresse dauerhaft zuzuordnen. Während des Gebastels ist mir mehrmals aufgefallen, dass sich die IPv6-Adresse von Iteration zu Iteration verändert hat, was sicher daran lag, dass ich zwischendurch immer auch Änderungen an der Konfiguration des LXC vorgenommen hatte. Das gab eine neue MAC-Adresse und basierend darauf dann eine neue IPv6-Adresse.
Wobei ich vorher untersuchen sollte, ob das auch jedes Mal bei einem Neustart des LXC schon passiert. Das wäre nur ein weiterer Grund, den passenden Konfigurationsparameter lxc.net.1.hwaddr in der config des LXC zu setzen. Glücklicherweise kann man in der /etc/lxc/default.conf einen Parameter setzen, der beim Erstellen von LXC auch zufällige MAC-Adressen generiert und eine solche in die config schreibt.
Firewall-Regeln! Jetzt, wo ein LXC exponiert ist, sollte er auch entsprechend geschützt werden. In unserem Fall dürften alle Ports außer 80 und 443 abgelehnt werden. Was bin ich froh, dass sowohl LXC wie auch systemd-nspawn dafür mittlerweile auf nftables setzen
Offene Fragen
Was passiert, wenn ein Container jetzt die ::1 anspricht? Es gibt ja die die /64-Route. Wenn erste Hinweise stimmen, dann interessiert sich das System nicht wirklich dafür, über welche Schnittstelle ein Paket für eine Adresse hereinkommt, die ihm zugeordnet ist – br0 war ja auch von außen anpingbar, obwohl eth0 und br0 nicht verbunden waren.
Hat sich der LXC jetzt per DHCPv6 konfiguriert oder per SLAAC? Ich könnte vielleicht schauen, ob die IPv6-Adresse nach EUI-64 gebildet wurde. Momentan ist mir noch ein wenig rätselhaft, wann DHCPv6 zum Einsatz kommt, zumal ich keine expliziten Konfigurationsoptionen zum Starten eines DHCPv6-Servers identifizieren konnte.
Brauche ich DHCPv6 überhaupt? Prefix und Routen werden ja offenbar per Router Advertisement vermittelt. Wie würde ich per DHCPv6 überhaupt weitergehenden Einfluss auf die Konfigurationen eines DHCPv6-Clients ausüben?
Manche der Fragen werde ich bestimmt nach meinem Urlaub angehen. Alles in allem war das eine sehr lehrreiche Erfahrung und wieder mal eine Erinnerung, warum ich so gerne mit meinem Kollegen zusammenarbeite.
systemd asncounter-service
Nach zwei Tagen habe ich mir mal angeschaut, was mein systemd-service zum Zählen von Zugriffen nach ASN denn so angestellt hat. Dabei fielen mir ein paar kleinere Fehler auf, die ich korrigiert habe.
Außerdem kam bei mir der Wunsch auf, auch auf der Kommandozeile schnell Zugriff auf die Analyse des asncounters zu kriegen und habe mir zwei kleine Skripte geschrieben. Da diese aber auch wissen müssen, wo die cachierten Logs liegen, habe ich die Umgebungsvariablen aus dem systemd-Service in ein EnvironmentFile=/etc/asncounter-service/env ausgelagert. Umbenannt habe ich den Service auch, weil ich nicht mehr als ein Verb im Namen haben wollte: count_asn_get_prefixes klang einfach falsch, asncounter-get-prefixes klingt besser.
Die aktuelle Version befindet sich in meinem Repository.
systemd-service zum Zählen von Zugriffen nach ASN
Ich will es wissen: Woher kommen die Zugriffe auf meinen Rootserver? Und stellt das ein Problem dar?
Die letzte Frage kann ich klar mit "nein" beantworten. Der Server langweilt sich die meiste Zeit. Aber neben meinem Rootserver habe ich noch einen virtuellen Server (VPS, virtual private server), der ein bisschen mehr zu tun hat und bei dem es ein Problem sein könnte, wenn da zu viel Mist aufläuft. Der Rootserver ist aber ein gutes Versuchskaninchen.
Anarcat hat letztes Jahr das Python-Programm asncounter veröffentlicht, das Logs aus verschiedenen Quellen nehmen kann, um sie zu analysieren und eine ASN-Statistik auszugeben. Im (englischsprachigen, aber gut verständlichen) Blogbeitrag befinden sich Erklärungen zu AS, ASN und BGP.
Der Server läuft derzeit noch mit Debian 12. Anarcat stellt in Aussicht, dass asncounter in Debian 14 in den offiziellen Repositorys enthalten seien könnte. Bis dahin ist die beste Installationsmethode wohl mittels pip bzw. pipx. Ich habe mich für letzteres entschieden. Der Einfachheit halber installiere ich gleich die Pakete mit, die bei der Installation von asncounter benötigt werden:
apt install pipx build-essential python3-dev
Ich mag es nicht, wenn pipx die virtuellen Environments und so in /root erstellt. Deswegen setze ich in der /root/.bashrc ein paar Variablen für pipx:
export PIPX_BIN_DIR=/usr/local/bin export PIPX_HOME=/usr/local/share/pipx eval "$(register-python-argcomplete pipx)"
Die letzte Zeile dient der Tabvervollständigung von pipx-Befehlen. Einmal kurz ausgeloggt und wieder eingeloggt, geht es weiter:
pipx install --include-deps asncounter
Das installiert den asncounter inklusive seiner Abhängigkeiten. Der Blogbeitrag erwähnt im tl;dr am Anfang eine Befehlszeile folgenden Formats:
tcpdump -q -i enp0s31f6 -n -Q in "tcp and tcp[tcpflags] & tcp-syn != 0 and (port 80 or port 443)" | asncounter --input-format=tcpdump --repl
Ich lese "tcpdump" jetzt nicht so wahnsinnig flüssig, aber ich erkenne eine Filterung nach TCP-Zugriffen auf Ports 80 und 443. Das soll mir für den Anfang reichen. Dummerweise hänge ich dann im REPL fest und muss die dazugehörige man-Page erstmal ein wenig gründlicher lesen, wo ich auf recorder.display_results() stoße:
>>> recorder.display_results() count percent ASN AS 7248 85.27 265269 MEGA TELE INFORMATICA, BR 1132 13.32 270606 R3 TELECOM, BR 25 0.29 54801 ZILLION-NETWORK, US 25 0.29 45102 ALIBABA-CN-NET Alibaba US Technology Co., Ltd., CN 15 0.18 209334 MODAT-01, NL 11 0.13 197540 NETCUP-AS netcup GmbH, DE 6 0.07 16276 OVH, FR 4 0.05 213438 COLOCATEL-INC Colocatel Network - High Bandwidth Dedicated Servers, SC 4 0.05 14061 DIGITALOCEAN-ASN, US 3 0.04 211607 RECORDEDFUTURE, US unique ASN: 26 count percent prefix ASN AS 1826 21.48 168.90.91.0/24 265269 MEGA TELE INFORMATICA, BR 1823 21.45 168.90.89.0/24 265269 MEGA TELE INFORMATICA, BR 1806 21.25 168.90.88.0/23 265269 MEGA TELE INFORMATICA, BR 1793 21.09 168.90.90.0/24 265269 MEGA TELE INFORMATICA, BR 310 3.65 177.37.19.0/24 270606 R3 TELECOM, BR 282 3.32 177.37.17.0/24 270606 R3 TELECOM, BR 273 3.21 177.37.18.0/24 270606 R3 TELECOM, BR 267 3.14 177.37.16.0/24 270606 R3 TELECOM, BR 25 0.29 148.178.64.0/20 54801 ZILLION-NETWORK, US 25 0.29 47.83.0.0/17 45102 ALIBABA-CN-NET Alibaba US Technology Co., Ltd., CN unique prefixes: 34 total lookups: 8500 total skipped: 0 total failed: 0
asncounter gibt also im Falle des Durchpipens von tcpdump nur auf explizite Anfrage Werte aus. Damit kann man sicher arbeiten, aber mir wird beim Gedanken, irgendwelche Sockets regelmäßig abzufragen, ein wenig flau im Magen. Langlaufende Prozesse, die ich verbrochen habe? Nein, danke :-).
Aber tcpdump minütlich Dinge erfassen lassen, die ich asncounter dann zum Analysieren vorwerfen kann? Klar, das sicher. Und so lernte ich heute von timeout, das genau das tut, was ich will:
timeout -sHUP 1m tcpdump -q -i enp0s31f6 -n -Q in "tcp and tcp[tcpflags] & tcp-syn != 0 and (port 80 or port 443)" > tcpdump4asncounter.log
Jetzt brauche ich nur ein Bash-Skript, das mir jede Minute eine Datei mit diesen Daten erstellt.
#!/usr/bin/env bash
CACHE_DIR=/var/cache/count_asn
IF="${INTERFACE:-any}"
DIR="${CACHE_DIRECTORY:-${CACHE_DIR}}"
printf "Interface set to %s.\n" "${IF}"
printf "Cache directory set to %s.\n" "${DIR}"
cleanup () {
#kill -s SIGTERM $!
exit 0
}
trap cleanup SIGINT SIGTERM
if [ ! -d "${DIR}" ]
then
install -d "${DIR}"
fi
printf "Starting logging loop …\n"
while true
do
CURRENT=$(date +%s)
timeout -sHUP 10s tcpdump -q -i "${IF}" -n -Q in "tcp and tcp[tcpflags] & tcp-syn != 0 and (port 80 or port 443)" > "/tmp/count_asn_${CURRENT}.log" 2> /dev/null
find "${DIR}" -type f -mtime +1 -delete
mv "/tmp/count_asn_${CURRENT}.log" "${DIR}/"
cat "${DIR}/"count_asn_*.log | /usr/local/bin/asncounter --input-format tcpdump --no-prefixes --output /etc/motd.d/01-asncounter.txt 2> /dev/null
done
Am Anfang werden ein paar Variablen initialisiert, die ich entweder per systemd übergebe oder eben auch nicht. Dann braucht es aber sinnvolle Defaults.
Ich habe feststellen dürfen, dass sich so eine while-true-Schleife nicht mit Strg+c abbrechen lässt. Vielleicht liegt es auch an timeout. Deswegen werden die Signale SIGINT und SIGTERM explizit abgefangen und in der cleanup()-Funktion behandelt. Das aktuelle tcpdump läuft aber noch bis zum Ende durch. Damit kann ich leben.
Der Dump wird erstmal nur nach /tmp geschrieben. Dann werden die Dateien entfernt, die älter als 1 Tag sind, bevor die neue Datei in den Cache geschoben wird. Der Cache-Inhalt wird dann asncounter zur Analyse übergeben, das Ergebnis wird nach /etc/motd.d geschrieben (Verzeichnis muss manuell erstellt werden). Und auf diese Weise lernte ich, dass pam_login auch die Dateien dieses Verzeichnisses ausgibt statt nur /etc/motd.
Natürlich muss das Skript ausführbar gemacht werden:
chmod +x /usr/local/bin/count_asn
Jetzt muss das Skript nur noch dauerhaft laufen. Ich benutze dafür gerne systemd. Schnell mal eine Vorlage im Web herausgesucht und an meine Bedürfnisse angepasst. Ich bin leider immer noch nicht so weit, dass ich das aus dem Ärmel schütteln kann:
# /etc/systemd/system/count_asn.service [Unit] Description=Count ASNs using asncounter and update motd After=network.target [Service] Type=simple Environment=INTERFACE=enp0s31f6 ExecStart=/usr/local/bin/count_asn Restart=always RestartSec=5 CacheDirectory=count_asn IgnoreSIGPIPE=no [Install] WantedBy=multi-user.target
Der Install-Abschnitt gibt wie immer an, an welcher Stelle beim Booten der Dienst gestartet werden soll, wenn er enabled wird. Im Unit-Abschnitt sagen wir an, dass der Dienst erst nach dem Erreichen des network.target gestartet werden soll. Verfügbarkeit von Netzwerk ist eine Wissenschaft für sich, aber hier sollte das passen.
Der wichtigste Teil ist hier IgnoreSIGPIPE=no, ansonsten klappt das Pipen der Daten an asncounter nicht. Das Skript kriegt mit der Umgebungsvariable INTERFACE noch die richtige Schnittstelle mitgeteilt.
Lohn der Mühe:
$ ssh root@hades Linux hades.fluchtkapsel.de 6.1.0-41-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.158-1 (2025-11-09) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. count percent ASN AS 21811 78.65 265269 MEGA TELE INFORMATICA, BR 5486 19.78 265410 JL INFORMATICA E TELECOM LTDA - ME, BR 108 0.39 14618 AMAZON-AES, US 71 0.26 197540 NETCUP-AS netcup GmbH, DE 43 0.16 8075 MICROSOFT-CORP-MSN-AS-BLOCK, US 40 0.14 202306 HOSTGLOBALPLUS-AS, GB 31 0.11 51852 PLI-AS, PA 17 0.06 206264 AMARUTU-TECHNOLOGY, SC 14 0.05 398705 CENSYS-ARIN-02, US 10 0.04 62068 SPECTRAIP SpectraIP B.V., NL unique ASN: 40 total lookups: 27730 total skipped: 152 total failed: 0 Last login: Fri Jan 9 18:05:35 2026 from 79.248.89.181
Ich werde beim Login mit der Statistik begrüßt. Das sieht mir jetzt robust genug aus, dass ich das auch auf meinem VPS einrichten kann. Dort läuft Arch Linux. Als erstes installiere ich pipx:
pacman -Sy python-pipx python-pip base-devel
python-pip ist nur dafür dabei, falls ich mal manuell in die venv schauen muss, und base-devel ist das Arch-Äquivalent zu Debians build-essential. Als nächstes kommen die Einträge in die .bashrc von oben gefolgt von einem Logout und erneuten Login.
Ich übertrage das Skript und den Service, passe die Schnittstelle an, erstelle das Verzeichnis /etc/motd.d und starte den Service. Nach ein paar Minuten gibt es dann auch hier Statistiken:
$ ssh root@persephone count percent ASN AS 651 58.97 265269 MEGA TELE INFORMATICA, BR 151 13.68 265410 JL INFORMATICA E TELECOM LTDA - ME, BR 113 10.24 24940 HETZNER-AS, DE 61 5.53 14618 AMAZON-AES, US 22 1.99 16276 OVH, FR 12 1.09 197540 NETCUP-AS netcup GmbH, DE 8 0.72 3320 DTAG Internet service provider operations, DE 8 0.72 63949 AKAMAI-LINODE-AP Akamai Connected Cloud, SG 8 0.72 15169 GOOGLE, US 7 0.63 14061 DIGITALOCEAN-ASN, US unique ASN: 52 total lookups: 1104 total skipped: 7 total failed: 9462
Deutlich weniger Betrieb. Das überrascht. Im nächsten Schritt muss ich dann mal schauen, ob ich aus diesen Daten sinnvolle Regeln für die Firewall ableiten kann. Auf beiden Systemen läuft nftables – das macht es mir ein wenig einfacher. Aber das ist eine Aufgabe für einen Folge-Eintrag ins Blog.
Dieser Blog-Eintrag wurde ohne Unterstützung generativer KI erstellt.
Fritz!Box WireGuard und systemd-networkd
Vor Jahren schon habe ich einfache WireGuard-Verbindungen zwischen meinem Heimserver und meinem virtuellen Server, damals bei Contabo, eingerichtet. Ich erinnere mich düster, dass ich den WireGuard-Schnittstellen eigene IP-Adressen zuweisen musste, über die dann das Routing eingerichtet wurde.
In diesem Eintrag werde ich Verbindungsschlüssel entfernen und IP-Adressen austauschen bzw. durch Labels ersetzen, die ihre Funktion beschreiben, damit das ggf. auf vergleichbare, aber nicht identische Situationen angewendet werden kann.
Die Situation
Bei mir liegen zwei Spezialfälle vor: Ich habe auf meinem Server ein paar Systemcontainer mit systemd-nspawn am Laufen. Diese hängen dort an einer Network Zone, die von systemd-nspawn gemanagt wird. Für vorhersagbare IP-Adressen läuft auf der Bridge-Schnittstelle der DHCP-Server von systemd-networkd. Der wird einfach mittels einer Drop-in-Datei aktiviert und konfiguriert.
# /etc/systemd/network/80-container-vz.network.d/00-dhcp.conf [Network] Address=192.168.1.1/24 Address=fd00:1::1/64 DHCPServer=yes IPMasquerade=both [DHCPServer] ServerAddress=192.168.1.1/24 EmitDNS=yes DNS=9.9.9.9 EmitRouter=yes EmitTimezone=yes Timezone=Europe/Berlin PoolOffset=99 PoolSize=150 [DHCPServerStaticLease] # nspawn 1 MACAddress=12:34:56:00:00:01 Address=192.168.1.101 [DHCPServerStaticLease] # nspawn 2 MACAddress=12:34:56:00:00:02 Address=192.168.1.102 [DHCPServerStaticLease] # qemu 1 MACAddress=12:34:56:00:01:01 Address=192.168.1.201
Die einzelnen statischen Leases könnten jeweils auch in eigenen Dateien stecken.
Die andere Besonderheit ist, dass die Fritzbox bei mir nicht für das DHCP zuständig ist. Das macht ein dnsmasq auf meinem Heimserver in einem systemd-nspawn-Container.
Wichtig ist, dass am Ende aus dem lokalen Netz hinter der Fritzbox via WireGuard auf die einzelnen Container zugegriffen werden kann.
## Konfiguration auf der Fritzbox Der wichtige Teil findet statt auf der Seite "Internet > Freigaben > VPN (Wireguard)" (Fritz-OS 8.21). Der Assistent wird mit der Schaltfläche "WireGuard®-Verbindung hinzufügen" aufgerufen.
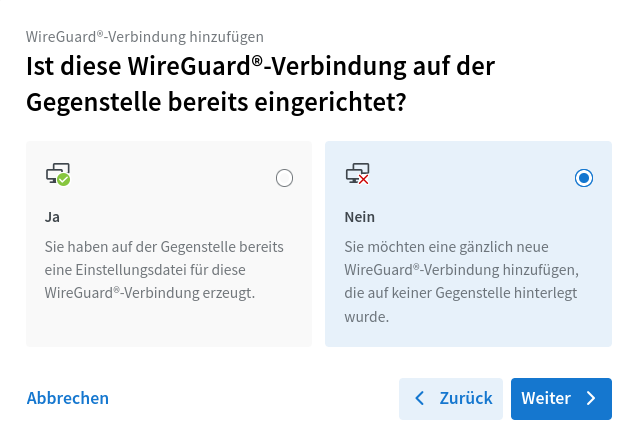
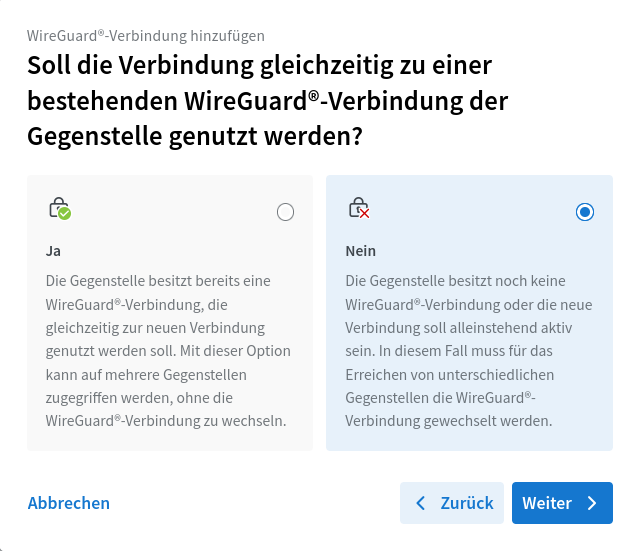
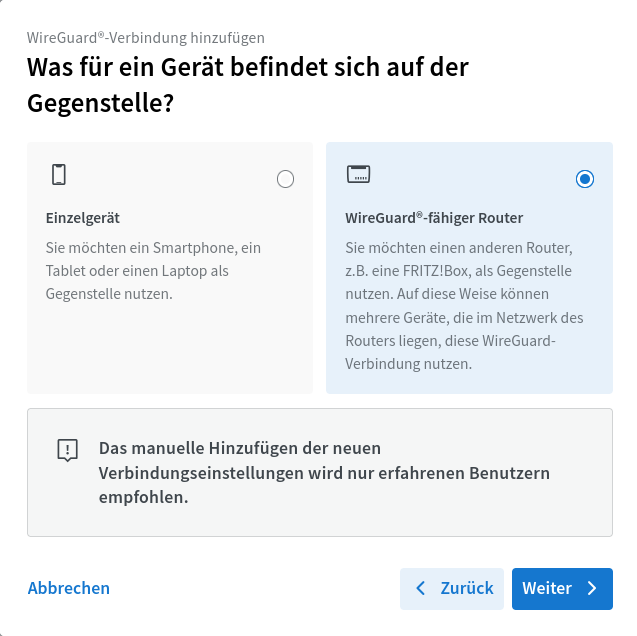
Effektiv musste ich in dem Assistenten immer die rechte Option wählen:
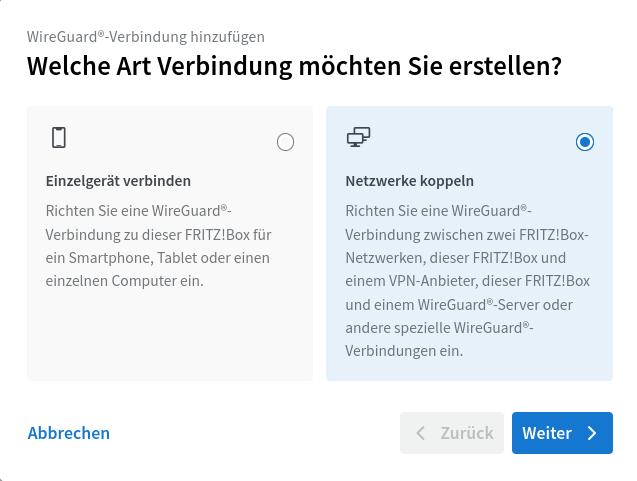
Welche Art Verbindung möchten Sie erstellen? → Netzwerke koppeln.
Ist diese WireGuard®-Verbindung auf der Gegenstelle bereits eingerichtet? → Nein.
Soll die Verbindung gleichzeitig zu einer bestehenden WireGuard®-Verbindung der Gegenstelle genutzt werden? → Nein. Ich habe nicht geschaut, was "ja" an der Stelle bewirkt. Ich nehme an, davon hängt ab, ob ich eine vollständige Konfiguration kriege oder nur einen Schnipsel zur Ergänzung.
Was für ein Gerät befindet sich auf der Gegenstelle? → WireGuard®-fähiger Router. Keine Ahnung, warum das abgefragt wird, wenn ich am Anfang "Netzwerke koppeln" ausgewählt habe. Ja natürlich muss da ein WireGuard®-fähiger Router sein.
Der Assistent warnt mich dann:
Das manuelle Hinzufügen der neuen Verbindungseinstellungen wird nur erfahrenen Benutzern empfohlen.
Naja, wir sind ja erfahren, nicht wahr?
Als nächstes vergeben wir einen Namen, unter dem die Verbindung geführt wird.
Der nächste Schritt ist ein wenig unklar. Der Assistent möchte eine Angabe der "DNS-Domains der WireGuard®-Gegenstelle". Nirgends scheint die Angabe eine Auswirkung zu haben. Ich kann nur mutmaßen, dass dieser Wert via DHCP als search domain verteilt wird. Wie eingangs erwähnt, kümmert sich ein anderes System hier um DHCP.
Im vorletzten Schritt fragt der Assistent nach den "IP-Einstellungen der Verbindung". Hier musste ich ein wenig experimentieren, um herauszufinden, was der Assistent damit meint. Letzten Endes funktionierte es mit der IP-Adresse der systemd-nspawn-Zone, deren Netzmaske (CIDR zu Netzmaske) und der ULA-IPv6-Adresse ebendieser Schnittstelle. Bis zu dieser Konfiguration hatte ich der Zonen-Schnittstelle überhaupt keine IPv6-Adresse vergeben, was zu ein bisschen Recherche-Arbeit geführt hat.
Im letzten Schritt gibt es ein paar Kästchen anzukreuzen oder auch nicht. In diesem Fall wird nichts davon gebraucht.
Wenn man zu lange brauchte seit der letzten Bestätigung, dass man berechtigt sei, Änderungen an der Konfiguration vorzunehmen, muss das jetzt nochmal bestätigt werden. Im Anschluss arbeitet die Fritzbox ein wenig und bietet dann den Download der erstellten Konfiguration an, was wir auch annehmen. Nach dem Download muss noch auf "Ok" geklickt werden. Der Assistent weist ein letztes Mal darauf hin, dass die geheimen Verbindungsdaten aus der Datei nicht wieder eingesehen werden können.
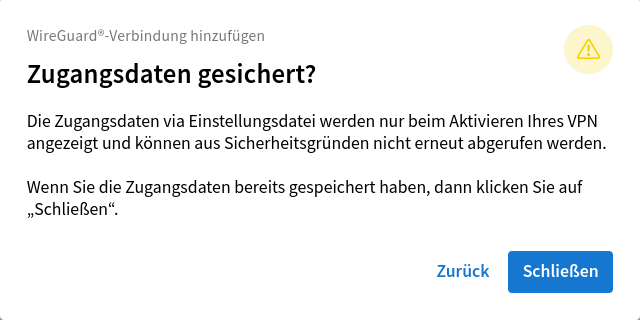
[Interface] PrivateKey = <privater Schlüssel des Servers> Address = 192.168.1.1/24,fd12:3456:7891::/64 DNS = <private IPv4 und IPv6 der Fritzbox> DNS = fritz.box [Peer] PublicKey = <öffentlicher Schlüssel der Fritzbox> PresharedKey = <geteilter Schlüssel der Verbindung> AllowedIPs = <private IPv4- und IPv6-Netze der Fritzbox> Endpoint = foobar.myfritz.net:52008 PersistentKeepalive = 25
Eigentlich brauchen wir die Datei gar nicht, aber sie beinhaltet die Werte, die wir für die Konfiguration mit systemd-networkd brauchen.
## Konfiguration von systemd-networkd auf dem Server
Die Konfigurationsdateien von systemd-networkd liegen üblicherweise in /etc/systedm/network/.
Die Verbindung wird auf drei Dateien aufgeteilt:
wg0.netdev-
Die Datei legt das Netzwerkgerät an. Sie beinhaltet die Verbindung zur Gegenstelle sowie alle für die Verbindung notwendigen Geheimnisse bzw. verweist auf entsprechende Dateien (vgl. man-Page systemd.netdev, Abschnitt Wireguard).
wg0.key-
Die Datei beinhaltet den base64-kodierten privaten Schlüssel des Servers für diese Verbindung.
wg0.network-
Hier wird ganz normal das Netzwerk auf der Schnittstelle
wg0konfiguriert – IP-Adressen, Routen und was sonst noch so anfällt (vgl. man-Page systemd.network).
Die Namen der Dateien sind beliebig wählbar. Allein bei dem privaten Schlüssel muss drauf geachtet werden, dass die Datei in der .netdev-Datei korrekt referenziert wird.
# wg0.netdev [NetDev] Name=wg0 Kind=wireguard Description=WireGuard tunnel wg0 [WireGuard] # Vermutlich unnötig, ist einfach auf den gleichen Port gesetzt, den die Fritzbox auch nutzt. ListenPort=52008 PrivateKeyFile=/etc/systemd/network/wg0.key [WireGuardPeer] AllowedIPs=192.168.178.1/24,fd12:3456:7890::/64 PublicKey=<öffentlicher Schlüssel der Fritzbox> PresharedKey=<geteilter Schlüssel der Verbindung> Endpoint=foobar.myfritz.net:52008 PersistentKeepalive=25
Die Werte für PublicKey und PresharedKey können einfach aus der heruntergeladenen Konfigurationsdatei kopiert werden. Tatsächlich benutzen WireGuard und systemd-networkd die gleichen Namen für die Werte, so dass sogar die Zeilen komplett kopiert werden können.
systemd-networkd möchte nicht, dass diese Datei weltlesbar ist, weswegen wir die Berechtigungen und Eigentümerschaft anpassen:
chmod 640 /etc/systemd/network/wg0.netdev chown root:systemd-network /etc/systemd/network/wg0.netdev
Das PrivateKeyFile beinhaltet einfach nur den Wert <privater Schlüssel des Servers> aus der Konfigurationsdatei ohne PrivateKey= oder ähnlichem. Netterweise ist der Wert bereits base64-kodiert, so dass dahingehend nichts weiter getan werden muss. Für die Datei verlangt systemd-networkd aber sogar, dass sie nicht weltlesbar ist:
chmod 640 /etc/systemd/network/wg0.key chown root:systemd-network /etc/systemd/network/wg0.key
Bei der letzten Datei, der wg0.network, ist systemd-networkd entspannter. Sie kann ruhig von allen gelesen werden.
# wg0.network [Match] Name=wg0 [Network] Address=192.168.1.1/24 Address=fd00:1::1/64 IPMasquerade=both [Route] Destination=<IPv4-Netzwerk der Fritzbox> [Route] Destination=<IPv6-Netzwerk der Fritzbox>
Aufmerksamen Leser*innen ist es sicher aufgefallen, und mir bereitet es auch Bauchschmerzen, aber es funktioniert tatsächlich: Die Schnittstelle wg0 erhält die gleichen Adressen und Netzmasken wie die Schnittstelle der systemd-nspawn-Zone.
Mit einem finalen networkctl reload wird die Schnittstelle aktiviert und der WireGuard-Tunnel aufgebaut.
Da die systemd-nspawn-Container als Default-Route die Adresse der Zonen-Schnittstelle konfiguriert haben, funktionieren Verbindungen von Seiten der Container sofort. Auch die Geräte hinter der Fritzbox können die Container ohne Probleme erreichen, da die Fritzbox –wie in den meisten Fällen– als Gateway konfiguriert ist.
Dieser Blog-Eintrag wurde ohne Unterstützung generativer KI erstellt.
Umtausch des Führerscheins mit der BundID
Seit Monaten piesackt mich die Ehefrau, dass ich doch endlich mal meinen Führerschein umtauschen soll. Durch meinen Beinbruch Anfang des Jahres hatte sich die Notwendigkeit dazu ein wenig verringert. Aber seit dem 19.1. habe ich effektiv keine gültige Fahrerlaubnis mehr. Aber jetzt, wo der Bruch so langsam verheilt ist, wird es doch dringlicher.
Meine Frau meinte, der Online-Umtausch sei eigentlich ganz einfach. Das stimmte mich zuversichtlich. Also schnell mal die Website des Landkreises aufgerufen und nach irgendwas mit Führerschein oder Fahrerlaubnis gesucht. Bei den häufig gestellten Fragen gab es zwar viele Antworten aber keinen Link zum Umtausch. Den fand ich dann bei den Dienstleistungen unter "F" wie "Führerschein, Umtausch". Alles in allem ging der Teil schneller als befürchtet.
Nirgends ein Link zum Online-Umtausch

Hier ist der gesuchte Link. Man muss nur denken wie ein Bürokrat.
Gleich zu Anfang wird mir angeboten, meinen Ausweis mit Onlinefunktion zum Identitätsnachweis nutzen zu können! Wow! Das zweite Mal nach der Krankenversicherung, dass ich ihn zum Einsatz bringen kann!
Vermutlich wäre es ohne Online-Identitätsnachweis schneller gegangen. Aber es ist ja auch das erste Mal
Frohen Mutes wähle ich im nächsten Schritt meine Nationalität und die einzige angebotene Option (Personalausweis mit Online-Ausweisfunktion), nur um dann gesagt zu bekommen, ich müsse mich mittels BundID authentifizieren.
*seufz*
Also probieren wir es damit. Abgesehen davon, dass die Erstellung einer BundID in dem Popup-Fenster ein wenig beengt ist, geht das eigentlich recht gut. Nur stolpere ich hier und da über den einen oder anderen Fallstrick.
Als erstes wundere ich mich, warum die Registrierung eine Verbindung zu localhost aufbauen will. Dann dämmert es mir, dass auf diese Weise mit der AusweisApp gesprochen werden soll. Also starte ich die AusweisApp, die es dankenswerterweise auch für Linux gibt, sogar als Flatpak. Spannendes Konzept übrigens: Die AusweisApp auf dem Rechner kann auf zweierlei Weise den Ausweis auslesen: Entweder über ein Kartenterminal mit Nummernblock, das ich nicht habe (auf Arbeit hätten wir eines), oder indem sie mit der AusweisApp auf dem Smartphone redet und das liest die Daten aus. Die beiden Geräte wollen einmalig gekoppelt werden, aber dann läuft das nach Eingabe der 6-stelligen PIN überraschend stabil. Auch die Erkennung des Smartphones im WLAN durch die AusweisApp auf dem Rechner läuft geschmeidig.
Leider mag das bereits geöffnete Popup-Fenster jetzt nicht mehr mit der AusweisApp reden. Also zurück, neu probiert, Fehler "eine Registrierung ist bereits im Gange" oder so ähnlich erhalten, alles angezündet und nochmal von vorn in einem eigenen Fenster auf id.bund.de. Das geht dann gut bis zur Eingabe meiner E-Mail-Adresse, die ich mit einem Code bestätigen soll – "Session wurde nicht gefunden" oder so ähnlich.
Also zurück, "registrieren" angeklickt. "Registrierung ist bereits im Gange". Tab schließen, neuen öffnen, nochmal von vorne. Jetzt geht es, und ich komme bis zum Ende durch. Ich habe eine BundID!
Ich bin mir sicher, die Authentifizierung für den Führerschein wäre auch ohne BundID technisch möglich, wurde aber nicht implementiert, um die Nutzung der BundID zu erzwingen. Aber ich will mal nicht so sein, Digitalisierung in Deutschland und so.
Jetzt klappt es auch mit der Anmeldung für den Führerschein. Natürlich merkt sich die BundID nicht, dass ich eine laufende Sitzung habe, und ich muss erneut eine Anmeldung durchführen inkl. AusweisApp auf beiden Geräten und dem Ausweis am Smartphone. Welchen Nutzen Benutzername und Passwort haben sollen, die ich bei der Registrierung bei der BundID vergeben musste, erschließt sich mir noch nicht.
Der Blog-Eintrag ist schon länger, als ich beabsichtigt habe, also versuche ich es kurz zu halten.
Der Ablauf für den FÜhrerschein-Umtausch besteht aus vier bis sieben Seiten, je nach Zählweise. Die ersten vier Seiten sammeln die Daten des bestehenden Führerscheins und, was für den neuen gebraucht wird. Die anderen Seiten sind dann Kontaktdaten und Bestätigung. Für jeden Schritt habe ich 5 Minuten, danach wird alles beendet, und ich muss wieder von vorn beginnen.
Nachdem ich das erste Mal ins Timeout geraten bin, habe ich mir angewöhnt, immer mal wieder vor und zurück zu navigieren über die Buttons in der Website (nicht die Navigation des Browsers!). Dabei gehen zwar die Daten auf der letztbesuchten Seite verloren, aber ich kann vorbereiten, was notwendig ist.
So musste ich beide Seiten meines Führerscheins fotografieren. Damit bin ich dann ins Timeout geraten. Dateien zugeschnitten und ordentlich benannt, vor und zurück navigiert, angemeldet, Fragen beantwortet, Bilder hochgeladen. Sie wollen ein biometrisches Passfoto. Ich habe noch eines von der Krankenversicherung, aber das muss ich erst aus einem PDF befreien (yay, pdfimages). Die Website findet, dass der Hintergrund nicht gleichmäßig genug sei – er ist weiß. Meine Unterschrift nach der Namensnennung befindet sich noch nicht auf dem privaten Laptop, sondern nur auf dem Arbeitslaptop, also vor und zurück, Treppe hoch, Laptop einschalten, Treppe runter, SSH, Ordner kopieren, feststellen, dass sie überall PDF, JPEG, PNG erlauben, nur nicht bei der Unterschrift, die nur JPEG sein darf. Also Unterschrift in JPEG konvertiert. Vorher vor und zurück. Foto und Unterschrift hochgeladen, fertig.
Kena nach anderthalb Jahren
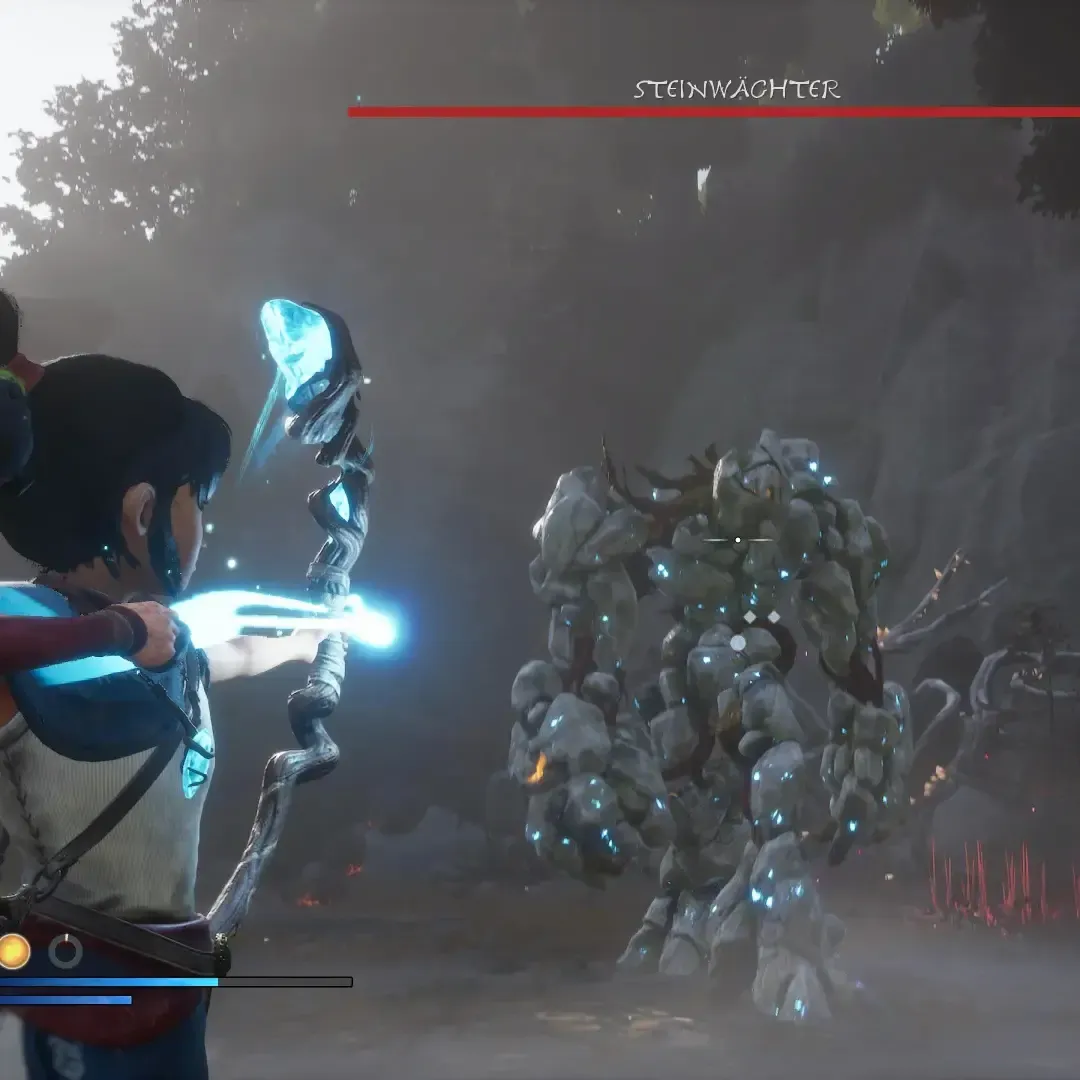
Kena und der Steinwächter.
Anmerkung: Dieser Beitrag ist zusammengestellt aus mehreren Posts im Fediverse. Für die bessere Auffindbarkeit veröffentliche ich das nachträglich auch hier.
Der Kampf gegen den Steinwächter bei Kena hat mich das Spiel vor anderthalb Jahren beiseitelegen lassen. Jetzt will ich das endlich mal zu einem Ende bringen, aber der Kampf bleibt fordernd. Und unfair, würde ich sagen. Nachdem ich Horizon Zero Dawn gespielt habe, merke ich erst, wie mies die Treffererkennung bei Kena ist. Immerhin, ich nähere mich Stück für Stück dem Ende seines Lebensbalkens immer weiter an. Frustrierend ist es dennoch.
Die Steuerung ist auch … anders. Wird eine Aktion wie Zielen unterbrochen, muss ich den Trigger erneut betätigen, statt dass das Spiel den weiterhin gedrückten Trigger annimmt.
An solchen Details merke ich dann doch den Unterschied zwischen einem polished game und einem, dass weniger polished ist.

Entspannung.
Anmerkung: Fortgeführt in einem neuen Thread im Fediverse. Das Datum des Beitrags setze ich auf das des ersten Beitrags des Threads.
Drei Tage ist es jetzt her, dass ich Kena wieder aufgegriffen habe. Nach anderthalb Jahren Pause habe ich natürlich nicht erwartet, sofort wieder auf die ganze Finesse zurückgreifen zu können, die ich zuvor in 28 Stunden Spiel erworben hatte. Mir war klar, dass ich die Steuerung wieder weitgehend erlernen musste: ausweichen, rennen, schnelle Schläge, starke Schläge, Bomben werfen, Pfeile verschießen, Rott anwenden, Rottpfeile, Sprungschläge – das kam alles wieder in Dutzenden verlorener Kämpfe gegen den Steinwächter. Ich habe mich nicht unter Druck gesetzt und das getan, wovon ich wusste, dass es mit der Zeit funktionieren wird: Dem motorischen Zentrum zu vertrauen, wie beim Tanzen, die einzelnen Schritte zu üben, dann sacken zu lassen, indem ich bewusst Pausen einlegte, wenn ich merkte, dass die Luft raus ist. Schlafen, Hirn die Verbindungen aufbauen lassen.

Rätsel!
Natürlich habe ich mich geärgert, aber wenn ich Ärger bemerkte, habe ich das eher als Anlass für eine kurze Pause gesehen. Ich habe da mit meinem Bruder immer ein leuchtendes Beispiel vor Augen, wie ich es nicht machen sollte 😄 (er hat meinen Lieblings-Joystick (und mehr) zerstört). Im oben verlinkten Thread habe ich ja schon meine Beobachtungen festgehalten, was mir an Kena weniger gefällt als an Horizon Zero Dawn. Zugegeben, HZD ist eher Action-RPG, während Kena eher Action-Adventure ist.
Für mich äußert sich das darin, dass die Kämpfe bei HZD taktischer sind als bei Kena, die dort dafür mehr Geschick erfordern. Das verfügbare Repertoire bei Kena ist an vielen Stellen im Spiel weitgehend vorgegeben, während es bei HZD vom Charakterfortschritt wie auch von der erworbenen Ausrüstung abhängt. Dennoch stelle ich beim konkreten Spielen mehr Ähnlichkeiten als Unterschiede fest.
Nach meinem aktuellen spielhistorischen Kenntnisstand würde ich sagen, dass sie alle ihre Wurzeln in den Tomb-Raider-Spielen haben. Natürlich waren diese auch "nur" dreidimensionale Versionen früherer Spielkonzepte. Aber die Kombination aus dreidimensionaler Umgebung mit Ausweichbewegungen für Nah- und Fernkampf sowie ein Repertoire an verschiedenen Angriffsoptionen und Interaktion mit der Umwelt unterscheidet sie deutlich von den Firstperson-Shootern. Oder gab es da vor Tomb Raider schon etwas?
Was ich jedenfalls sagen wollte: Es war erfolgreich. Gestern habe ich es erst spät geschafft, den Steinwächter so weit zu erschöpfen, dass er in seine zweite Kampfphase eintritt, heute habe ich ihn fast bei jedem Kampf so weit heruntergekämpft. Wenn ich es heute nicht geschafft hätte, dann auf jeden Fall morgen. Endlich kann ich Kena weiterspielen. Auch wenn es nicht so poliert sein mag, ist es ein bezauberndes Spiel, in dem ich gerne die eine oder andere Stunde verbringen will.

Endlich Ruhe in der Schmiede!
Mass Effect – Gedanken
Fangen wir mal mit meinen ersten Eindrücke zu Mass Effect an, wie ich sie am 18.Februar bei Facebook festgehalten hatte. Das Datum dieses Beitrags setze ich grob auf den Zeitpunkt, an dem ich Horizon Zero Dawn beendet habe, denn das hat mich dazu gebracht, noch einmal über Mass Effect nachzudenken.

Erzählerstimme: Es waren eher ein Dutzend schlecht vertuschter Skandale.
Zum Abendessen habe ich #MassEffect mal beendet.
Meine ersten Eindrücke: Neben meinen Squad-Mitgliedern sind die einzigen weiblichen Charaktere, die nicht total unpraktisch bodenlange Kleider tragen, Dr. Michel und die Crewfrau, die mir den Zutritt zur Normandy verweigert.
Die Kleider interpretiere ich auch als modische Übernahme von den Asari, da sie für meinen Geschmack nicht wie das Ergebnis menschlicher modischer Entwicklung aussehen.
Generell scheinen auf der Citadel alle weiblichen Charaktere entweder Menschen oder Asari zu sein. Ich habe keine Tularianer oder Sarianer oder sonst was gesehen, die ich als weiblich gelesen hätte. Volus, Elcor, Hanar – sie wirken alle männlichen Geschlechts. Da es bei den Asari explizit erwähnt wird, dass die Spezies exklusiv weiblich ist, nehme ich an, dass sie geschlechtliche Besonderheiten bei den anderen Völkern erwähnt hätten. Natürlich kann es sein, dass Geschlechter bei anderen Völkern für Menschen nicht erkennbar sind. Das wäre mal ganz nett, hätte aber auch eine Erwähnung wert sein können.
Generell scheinen nur Spielercharaktere und ganz besondere NSC bei den Menschen nicht einem 08/15-Modell zu folgen, wobei viele Frisuren bei den Frauen sehr ähnlich sind. Ja, ich habe mir die männlichen Statisten nicht so genau angesehen, gebe ich zu.
Auffällig finde ich weiterhin, dass es zwar vereinzelte PoC-Menschen gibt –allen voran Captain Anderson–, ansonsten aber die dominante Hautfarbe eher käsig-kaukasisch ist. Bathia, der die Leiche seiner Frau haben wollte, war die andere bemerkenswerte Ausnahme. Und ich glaube, in der Botschafter-Lounge saß noch ein BPoC-Mann.
Die Kombination aus Beinahe-Einheitskleid, Einheitsfrisur und Einheitshautfarbe sorgt für ein, sagen wir mal, recht gleichförmiges Bild (um nicht zu sagen "einfallsloses"). Ja, ich verstehe, man wollte wenig Ressourcen auf Hintergrund-Design verschwenden. Aber selbst bei den Asari gibt es mehr Hauttöne als bei den menschlichen Statisten. Und bei den Kleidern haben sie auch ein wenig an den Farbpaletten gespielt, das hatte doch auch bei der Hautfarbe drin sein können.
Was mich total kirre macht, sind die fetten Lidstriche bei den menschlichen Frauen. Jede einzelne, ob Zivilistin oder Soldatin, läuft mit Lidstrich umher. Natürlich können auch Soldatinnen Make-up tragen, aber dass da keine Varianz drin ist, zeigt mMn, dass da irgendwelche Männer mit eigenwilligen Vorstellungen von weiblichen Charakterdesigns die Entscheidungen getroffen haben.
Ich werde nach diesem Fokus auf die weibliche Repräsentation beim nächsten Mal auf die männliche achten. Meine Erwartungen sind da gering. Vielleicht mehr Charakterdesigns, individuellere Gesichter, aber grundsätzlich öde Outfits in öden Farben mit konventionell männlicher Darstellung.
Ansonsten habe ich bei der Erkundung der Citadel starke Assoziationen zu Knights of the Old Republic. Es wirkt ein wenig so, als wäre die Absicht gewesen, ein Setting zu entwickeln, das die Vielfalt, Fortschrittlichkeit und Atmosphäre von Star Wars KOTOR einfängt, ohne Star Wars zu sein, aber eine eigenständige Geschichte erzählt. Das ist explizit kein Vorwurf. KOTOR war ein großartiges Spiel, das zeigte, dass man mit dem Setting mehr machen kann als LucasFilm gewagt hat. Und die Atmosphäre, der Flavour bietet noch viel mehr Raum.
Natürlich sind auch Parallelen zu Babylon 5 zu sehen, weniger von Star Trek. Der abzusehende Fokus auf die galaktische Geschichte wird früher oder später auch Ähnlichkeiten zu Star Control 2 und bestimmt auch Starflight zeigen, wenn auch die letztgenannten mehr Mut beim Design der Aliens zeigten (wobei "Design" bei einem EGA-Grafik-Spiel aus den 80ern schon eine sehr mutige Wortwahl darstellt). KOTOR meets B5 trifft es im Moment aber noch am besten.

Am Anfang wirkte alles noch so überschaubar.
Ich habe im Anschluss fast zwei Monate lang die Mass Effect Legendary Edition gespielt, die aus allen drei Teilen und meines Wissens allen DLC besteht. 207,9 Stunden habe ich damit laut Steam verbracht. Aber ich habe die Spiele nicht weiter bei Facebook kommentiert. Weil ich in meinen ersten Gedanken meinem Gefühl nach recht harsch über manche Aspekt geurteilt habe, will ich das hier noch "schnell" abhandeln.

In Sachen Hautfarben gibt es im Verlauf noch ein bisschen mehr Abwechslung, aber der Fokus bleibt doch auf sehr weißer Haut. Die weiblichen Körper sind weitestgehend identisch, konventionelle Schönheiten. Jack in Mass Effect 2 wirkt dürrer, sehniger, drahtiger, aber richtig rundliche Körper unterschiedlicher Größe gibt es nicht. Abseits der Citadel gibt es auch andere Kleidung für Frauen, sogar schon auf der Citadel. Tatsächlich scheint es für jeden Abschnitt dort andere Outfits zu geben.
Bei den Männern gab es von Anfang an ein wenig mehr Variation bei den Gesichtern, die Figuren wirken aber auch größtenteils identisch. In den Teilen 2 und 3 bessert sich das alles ein wenig.
Repräsentation menschlicher Vielfalt ist bei einem SF-Setting für mich mittlerweile ein neuralgischer Punkt, und da schwächelt Mass Effect in meinen Augen. Aber das ist ja immer noch in bester Tradition der großen Vorbilder, wo Spezies schablonenhaft dargestellt werden.
Immerhin sind die Spezies dann doch nicht alle monolithische Blöcke, sondern es werden Individuen mit eigenen Bedürfnissen, Zielen und Methoden dargestellt, auch wenn sie teilweise eher ungelenk wirken. In Anbetracht des Alters des ersten Teiles finde ich das alles aber noch nachvollziehbar.
Die anderen beiden Teile?
Spielerisch finde ich die gesamte Trilogie großartig, das möchte ich vorweg schreiben. Was es mir schwer macht, Mass Effect als großen Wurf zu bezeichnen, sind die Auswirkungen der Entwicklung der Spiele auf die Story. Dieser Thread bei Reddit führt viele der Probleme auf. Dass am Ende die zahlreichen Entscheidungen nur wenig Auswirkungen auf die Quantität der Enden, sondern nur auf die Qualität haben, finde ich persönlich verschmerzbar. Bei einem Spiel dieser Länge und bei meinem Spiele-Backlog ist meine Motivation zum erneuten Durchspielen eher gering.
Nein, ich hatte eher irgendwann nur noch zerknirscht neue Details über die Story und insbesondere die Hintergrundgeschichte zur Kenntnis genommen. Was mich dann total vom Glauben hat abfallen lassen, war, dass ich nachlesen konnte, wie dieser oder jener Inhalt Teil eines DLC gewesen sein soll, wo ich mich fragte, was der Schwachsinn soll.

Party!
Ich habe oben mehrere potentielle Vorbilder genannt. Und Mass Effect hat es leider nicht geschafft, mir eine Hintergrundgeschichte zu liefern, wie einst die von den Leghk, die dem Uhl zu Opfer fielen, oder was das Endurium tatsächlich ist. Oder auch, wie die Ur-Quan begannen der Eternal Doctrine zu folgen, die sie gegen ihre Kohr-Ah-Cousins auf dem Path Of Now And Forever verteidigten. Die Motivation der Reaper bleibt bis zum Ende … ein Witz. Ich würde gerne eine weniger despektierliche Wortwahl finden, aber alles andere, was mir einfällt, fühlt sich unangemessen an. Selbst die Motivation von Schatten und Vorlonen fühlt sich im Rahmen der Story von Babylon 5 nachvollziehbarer an.
Ich glaube den Menschen, die an der Entwicklung beteiligt waren, dass sie andere und auch größere Pläne insbesondere für Mass Effect 3 hatten. In einem Kommentar zu meinem Beitrag, in dem ich mein Durchspielen von Horizon Zero Dawn verkündete, schrieb ich:
Stimmt, MEs Entwicklung fällt ja in die Zeit, wo Monetarisierung durch DLCs so Richtung Fahrt aufnahm. Ich habe ja "nur" die Legendary Edition gespielt, die ja alles enthielt. Und erst nachdem ich die LE gespielt hatte, bzw. nach dem jeweiligen Teil, las ich so ein bisschen, was die einzelnen DLCs eigentlich beinhaltet hatten, und teilweise empfand ich das schon als extrem lächerlich.
Ich erinnere mich an Expansion-Packs von Wing Commander 1 auch WC2 (Secret Mission resp. Special Operations), die ja ihr jeweiliges Hauptspiel um jeweils eine komplette Kampagne und auch neue Schiffe ergänzt haben. Und ich sehe jetzt bei HZD wie sie mit FW für mich zusätzliche 20 bis 30 Stunden an Spiel integriert haben. Dahingehend ist albern, was sie bei ME3 fabriziert haben. Der letzte Proteaner ein DLC? Ernsthaft? Dafür wurden die Spieler*innen zur Kasse gebeten? Erst einmal waren das vielleicht ein bis zwei Stunden zusätzliches Spiel, andererseits war das so elementar, dass das nie ohne diese Inhalte hätte verkauft werden dürfen. Leviathan wiederum wirkte einfach nur drangeklatscht. Und komplett hätte ich auf den Silversun-Strip-Kram verzichten können. Die ganze Jagd auf den Shepherd-Klon hatte irgendwie so die Atmosphäre einer Comedy-Episode in einer ansonsten ernsten Serie. Ja, ich musste zwischendurch lachen, aber es wirkte … unpassend. Ich nehme an, der Silversun Strip diente eher so als Hub für die Multiplayer-Komponente, die ich ja (glücklicherweise) nicht erleben konnte.
Aber bei allem Verständnis für die Schwierigkeit des Studios bei der Entwicklung: Die Story fängt stark an, wird aber schwach und schwächer, je mehr man von ihr erfährt. Das hätte nicht sein müssen. Die Motivation der Reaper ist dämlich und der Grund für ihre Existenz ist Blödsinn.

Das sind schon Szenerien mit Atmosphäre.
Ich werde sicher niemandem vorschreiben, dass meine Meinung zur Story die endgültige Wahrheit zu sein hat. Ich werde auch niemanden dafür verurteilen, wenn sie oder er die Story toll findet. Die Mass-Effect-Trilogie ist immer noch eine tolle Spielereihe, die sich sehr geschmeidig spielte (vielleicht abgesehen vom Inventarmanagement im ersten Teil). Atmosphärisch war sie großartig, mir trübte nur die Story den Gesamteindruck.
Spannenderweise hatte ich vor mehr als 10 Jahren schon einmal etwas zu Mass Effect gelesen und auch bei Facebook gepostet: The Problem With Modern Games. Es hat nur am Rande mit meiner Beurteilung zu tun, aber ich finde das Geschriebene durchaus gerechtfertigt.
Bleeding Love
Note: This post is compiled from several posts in the Fediverse. To make it easier to find, I also published it here afterwards. I set the date of the post to the date of the first post of the thread.
I've been to an international Vampire: The Masquerade LARP event the last few days, and I'd been assigned the role of a 3000 year old vampire who only longed to be reunited with his love whom he was forced to betray shortly after meeting her, still a mortal man back then. For 3000 years they avoided a direct encounter, instead putting pawns against each other, causing catastrophic events in their wake.
On the last night of the event, the great reconciliation between the two was scheduled and I put a lot of effort into evoking the emotional landscape of not having met her for three millennia. It was an emotional rollercoaster of pain, guilt and regret, of forgiveness, bliss, happiness – and love. And finally of loss, once again. I jokingly called it the happiest an hour and a half of his undead existence, and my counterpart made it easy for me to act these moments.
I not only heard of "The Bleed" before, I experienced it before, too. Feelings "bleeding" from the game's roles into their actors. But until now it's been mostly negative feelings – anger, aggression, contempt, fear, but also some positively connoted emotions as joy, arousal and the like. These were easy to deal with, to put aside. I knew they would wear off. And it's easy because they dissonate with the real life connections to the fellow actors.
But as I wrote before, I put special effort into evoking the emotions for this role as love was the event's central theme and deemed it worth this effort. And everybody who knows love knows it's a feeling worth every effort. And so I evoked love stalled for 3000 years.
I only met my counterpart for this event during this event. While her being a wonderful person had been helpful for the acting, it doesn't really help getting over the Bleed, and, even worse, the real life connection is practically non-existent.
Now, there's an emotional gap, an emptiness following the bliss of experiencing love as old as history (and nobody can prove me wrong on this one, don't even try). Sure, it will pass, too, but at the moment it weighs heavy on my heart. I'm not even certain what direction to take with this feeling. In contrast to real life love which besides thwarted by death always contains a glimmer of hope this love is completely fictional and thus without any hope. The persons involved don't even exist.
There are options, though. The emotion is real nonetheless and I could direct it at my wonderful wife. But this love was a young man's love, a foolish love, love burning hot, just stalled without hope of maturing beyond this stage. It appears unseemly to put her up with that. Love does not need symmetry but asymmetric love needs consent.
I could break down this feeling and somehow use it to fuel my real life feelings.
Or I could overanalyze this feeling. Maybe I'm not really good at "feeling".
Kontrollverlust
Ich schätze, Kontrolle kann man nur verlieren, wenn man vorher glaubte, sie besessen zu haben.
Ein einfaches Resümee, das Michael Seemann hier zieht. Ich sehe in diesem kurzen und knappen Befund aber ein Phänomen, das auch andere Bereiche umfasst, als mspr0 hier umreißt.
Ich frage mich bei solchen Aussagen ja immer: Habe ich Kontrolle über mein Leben? Über mein Umfeld? Habe ich die Kontrolle verloren? Ich finde die Fragen spannend, weil die aktuellen politischen Entwicklungen in Deutschland oft mit Aussagen einhergehen, dass Menschen empfänden, die Kontrolle über ihr Leben verloren zu haben. Gehe ich in mich, muss ich die Fragen mit "nein", "nein" und "hatte ich nie" beantworten.
Das ist natürlich sehr verallgemeinert. Es gibt Bereiche in meinem Leben, über die ich die Kontrolle habe, über andere habe ich sie nicht. In wiederum anderen Bereichen habe ich gute Chancen, Kontrolle zu erlangen, wenn ich mich engagiere.
Politisch und wirtschaftlich sah ich mich jedoch nie in der Position, Kontrolle zu haben. Ich empfand das auch nie als schlimm, denn Menschen sind soziale Tiere: Wir können uns in Gemeinschaften einbringen, aber keine Kontrolle über sie ausüben. In der Wirtschaft gibt es das Phänomen, dass einzelne Individuen ein Maß an Kontrolle erlangen können, das sicher den Eindruck erwecken kann, tatsächlich Kontrolle zu haben. Und es gibt den Mythos, dass, wer sich nur genug anstrenge, seines eigenen Lebens Herr werden können.
Als Mann mag ich mich da weit aus dem Fenster lehnen, ich wag es aber trotzdem. Ich denke, gerade beim letzten Punkt gibt es eine stark gegenderte Schieflage, denn Kontrolle zu haben gehört zur männlichen Rollenvorstellung, oder scheint es zumindest. Frauen lernen sehr früh, sich in Gewässern zu bewegen und bewegen zu müssen, wo sie keine Kontrolle ausüben können. Vielleicht hat das auch Auswirkungen auf die Berufswahl; ich will den Gedanken später nochmal aufgreifen.
Männer ziehen einen großen Teil ihres Selbstverständnisses daraus, von sich behaupten zu können, sie hätten die Kontrolle – über sich, über ihr Leben, über ihr Umfeld. Zu akzeptieren, dass andere über das eigene Leben entscheiden könnten, wird als unmännlich und sogar emaskulierend empfunden. In vielerlei Hinsicht bedeutet "Kontrolle zu haben", bekannte Umstände navigieren zu können. Unter verändernden Umständen jedoch taugen die eingeübten Navigationsfähigkeiten nicht mehr, es folgt das Gefühl des Kontrollverlusts und im Falle von konventionell männlich denkenden und fühlenden Männern wohl auch das Gefühl eines Angriffs auf die eigene Männlichkeit.
Frauen haben sich, wie ich oben erwähnt habe, früh damit arrangiert, weniger Kontrolle über ihr Umfeld zu haben, und orientieren sich eher im Rahmen des Möglichen der jeweiligen Situation. Frauen definieren ihre Geschlechtsperformance nicht in dem Umfang wie Männer darüber, Kontrolle über ihr Leben zu haben.
Jetzt gibt es eine Partei des Kampfes gegen den empfundenen Kontrollverlust: Es ist die Alternative für Deutschland, die AfD. Die AfD ist das Sammelbecken all derer, die das Gefühl des Kontrollverlustes haben. Die Welt verändert sich, und die AfD macht das Versprechen, die Welt wieder auf den gewohnten Pfad zurückführen, eine gefühlte alte Ordnung wiederherstellen zu können.
Ich bin kein Politwissenschaftler, meine Aussage ist kein Absolutum, sondern nur meine Sichtweise, der Versuch, Sinn zu erzeugen aus dem, was ich sehe.
Die AfD ist natürlich mehr als nur das. Sie ist, was sie vorgibt zu sein, sie ist eine Projektionsfläche für Mitglieder und für Wähler*innen, für Gegner*innen und Beobachter*innen, und somit ist sie auch das, was auf sie projiziert wird.
Aber "Kontrollverlust" ist auch ein Schlagwort, das aus den Reihen von AfD und ihren Sympathisant*innen zu hören ist. Die Flüchtlinge ab 2015, die Alternativlosigkeit in den Merkeljahren, die Klimakrise, die Pandemie – es gibt vieles, was instrumentalisiert werden kann, um einen Kontrollverlust herbeizureden.
Es gibt einen Gendergap bei den Unterstützer*innen der AfD. Es gibt sie auch bei den Wähler*innen der Republikaner. Es gibt ihn in der Parteipräferenz bei den Erstwähler*innen. Jungen und Männer neigen viel stärker dazu, Parteien zu wählen, die die Geschichte von der Kontrolle über das eigene Leben propagieren oder auch den Kontrollverlust beklagen. Die Republikaner fordern die Mauer an der Grenze nach Mexiko, und sie werfen ihren politischen Gegnern immer wieder vor, das Land nicht im Griff zu haben. Law & Order als Form von Kontrolle spricht generell eher Männer an als Frauen.
Kontrolle ist ein Weg, Sicherheit zu erlangen. Die beiden Begriffe sind nicht synonym, das eine folgt nicht aus dem anderen, sie bedingen sich vielleicht nicht einmal gegenseitig, aber sie sind assoziativ dicht beisammen.
Veränderungen verunsichern. Unsicherheit deutet an, keine Kontrolle zu haben.
Wer auch Kontrollverlust verspürt, wer auch die wählt, die Gewohntes zu konservieren versprechen, sind ältere Menschen. Es heißt, man werde konservativer, je älter man wird. Alter bedingt, im Laufe des Lebens mehr Veränderungen in der eigenen Lebenszeit angehäuft zu haben. Der Schock der Veränderungen ist natürlich umso größer, je länger man sein Leben leben konnte, ohne bewusst die Veränderungen um einen herum wahrnehmen zu müssen. Wer ein Leben von 60 Jahren führen konnte, in dem Homosexualität nicht vorzukommen schien, kriegt dann die Veränderungen von 40 bis 50 Jahren mit einem Schlag serviert.
Ich kann mir vorstellen, dass das ein sehr privilegiertes Leben war.
Wer 40 Jahre im Kohleberg- oder -tagebau geschuftet hat, um dann erst lernen zu müssen, dass die eigene Arbeit Anteil am Klimawandel trägt, kann davon auch komplett überfordert sein.
Wenn die Opfer unseres Wohlstandes vor der Tür stehen, und wir uns der Wahrheit stellen müssen, dass wir nicht nur geschaffen, sondern auch ausgebeutet haben, dann sind auch das Erkenntnisse von Jahrzehnten auf wenige Augenblicke komprimiert.
Die Augen vor Veränderungen verschließen zu können, ist ein Privileg.
Es ist wohl nur zu verständlich, wenn sich Menschen um Sicherheit in ihrem Leben bemühen. Und Kontrolle über das Umfeld auszuüben, ist eine Art, diese Sicherheit erlangen zu wollen. Für Frauen sind Männer ein Quell der Unsicherheit, männlich dominierte Arbeitsumfelder ein beständiger Kontrollverlust, der sich leichter in weiblich dominierten Arbeitsumfeldern bewältigen lässt. Safe spaces, von rechter, konservativer und männlicher Seite gerne verspottete Bereiche von lesbischen, schwulen, bisexuellen, trans, queeren und anderen Menschen, um Sicherheit durch Kontrolle des Umfeldes zu erzeugen. Auch People of Color haben sich ihre safe spaces errichtet, um nicht der Unsicherheit durch Weiße Menschen ausgesetzt zu werden.
Für viele Menschen ist Unsicherheit durch Unkontrolle Alltag. Und diejenigen, die den Kontrollverlust am lautesten beklagen, sind für diese Menschen nur allzuoft in der Vergangenheit der Grund für die Unsicherheit.
Ich stimme mspr0 zu. Kontrolle kann man nur verlieren, wenn man vorher glaubte, sie besessen zu haben. Ich möchte Kontrolle aber auch als Selbstlüge, als Illusion betrachten, zumindest für das Gros der Menschen. Unter großem Einsatz von Ressourcen lässt sich vielleicht individuelle Kontrolle erzeugen, aber ich wage zu behaupten, dass das für die meisten Menschen keine realistische Perspektive ist.
Ich persönlich neige dazu, die Zustände der Vergangenheit nicht zu idealisieren, und flexibel und spontan auf veränderte Umstände zu reagieren. Für Segelmetaphern bin ich im Thema nicht tief genug drin, aber Stürmen trotzt man wohl nicht, indem man sich ihnen entgegenstemmt.